导读:实时或者准实时的海量数据分析对于很多应用来说都是很难做到的,一方面是数据量太大,另一方面是分析条件多变。本文是Cloudflare在处理DNS查询分析的时候,作出的技术选型和踩过的坑。
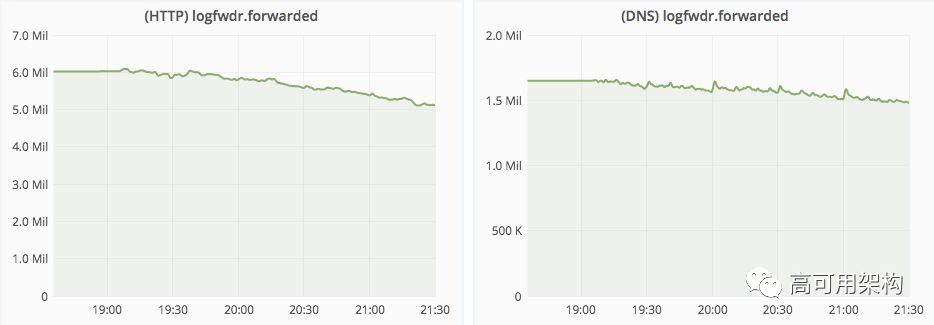
上周五,我们宣布了所有Cloudflare DNS分析工具。 由于我们的规模很大(当你读完这篇文章的时候,Cloudflare DNS将处理数以百万计的DNS查询) 我们必须非常有创意的解决该问题。 在本文中,我们将介绍DNS分析工具的组件,这些组件帮助我们每月处理数以万亿计的日志。
Cloudflare已经有一个用于HTTP日志的数据管道。我们希望DNS分析工具可以利用该功能。每当边缘服务处理一个HTTP请求时,它就会以Capn Proto格式生成一个结构化的日志消息,并将其发送到本地多路复用服务。考虑到数据量,我们只记录部分DNS消息数据,只包含我们感兴趣的数据,例如响应码,大小或query name,这使得我们每个消息平均只保留约150字节数据。然后将其与元数据处理(例如在查询处理期间触发的定时信息和异常)融合。在边缘融合数据和元数据的好处是,我们可以将计算成本分散到成千上万的边缘服务器,并且只记录我们需要的信息。
多路复用服务(称为“日志转发器”)正在每个边缘节点上运行,从多个服务组装日志消息并将其传输到我们的仓库,以便通过TLS安全通道进行处理。运行在仓库中的对应服务将日志接收并解分解到几个Apache Kafka集群中。Apache Kafka用于生产者和下游消费者之间做缓冲,防止消费者故障或需要维护时的数据丢失。自0.10版本以来,Kafka允许通过机架感知分配副本,从而提高对机架或站点故障的恢复能力,为我们提供容错的未处理消息存储。
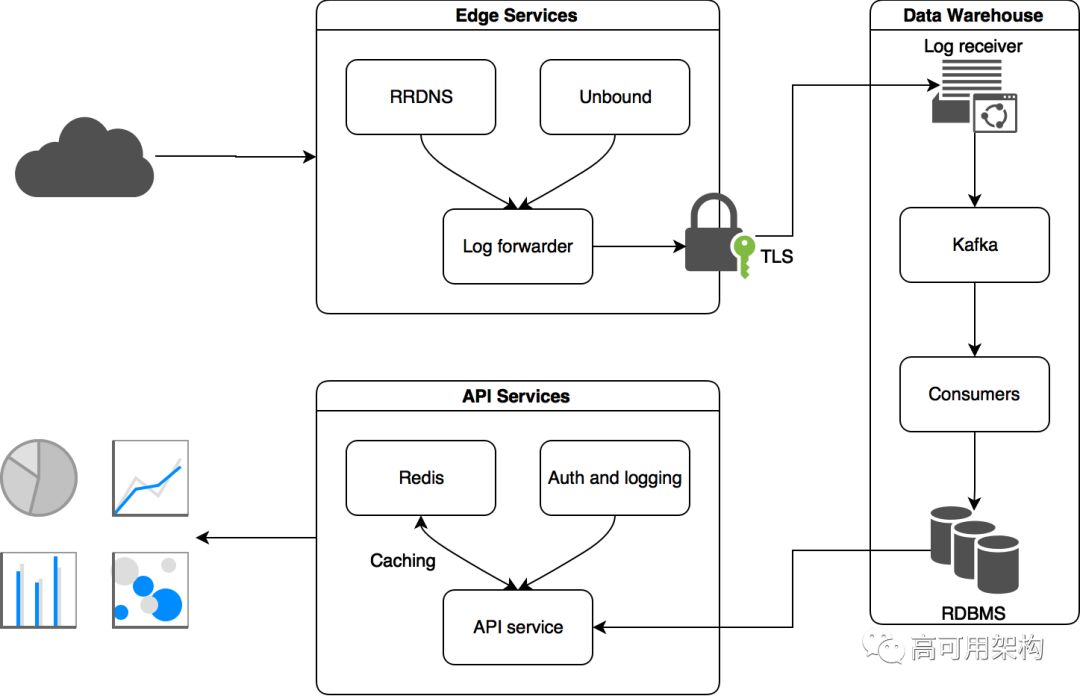
拥有结构化日志队列使我们能够追溯性地查问题,而不需要访问生产节点。 在项目的早期阶段,我们会跳过队列并找到我们所需的粗略时间段的偏移量,然后将数据以Parquet格式提取到HDFS中,以供离线分析。
HTTP分析服务是围绕生成聚合的流处理器构建的,因此我们计划利用Apache Spark将日志自动传输到HDFS。由于Parquet本身不支持索引以避免全表扫描,因此在线分析或通过API提供报告是不切实际的。虽然有像parquet-index这样的扩展可以在数据上创建索引,但也不能实时运行。鉴于此,最初的设计是仅向客户显示汇总报告,并保留原始数据用以内部故障排除。
汇总摘要的问题在于,它们只能处理基数较低(大量唯一值)的列。通过聚合,给定时间范围内的每个列都会扩展到很大的行数(与唯一条目个数相等),因此可以将响应码(例如只有12个可能的值,但不包含查询名称)进行聚合。如果域名受欢迎,假设每分钟被查询1000次,那么可以预期每分钟做聚合可以减少1000倍的数据,然而实际上并不是这样。
由于DNS缓存的存在,解析器在TTL期间不会进行DNS查询。 TTL往往超过一分钟。因此,服务器多次看到相同的请求,而我们的数据则偏向于不可缓存的查询,如拼写错误或随机前缀子域名攻击。在实践中,当用域名进行聚合时,我们可以看到最多可以减少为原来的1/60的行数,而多个分辨率存储聚合几乎可以抵消行减少。使用多个分辨率和键组合也可以完成聚合,因此聚合在高基数列上甚至可以产生比原始数据更多的行。
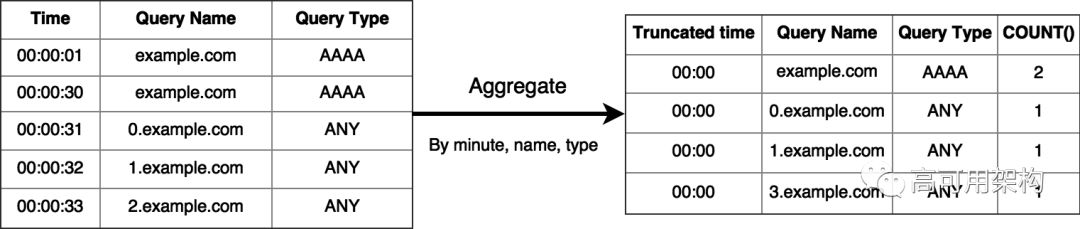
由于这些原因,我们首先在zone层次上汇总日志,这对于趋势分析来说已经足够,但是对于具体原因分析来说则太过粗糙。例如,我们正在调查其中一个数据中心的流量短暂爆发。具有未聚合的数据使我们能够将问题缩小到特定DNS查询,然后将查询与错误配置的防火墙规则相关联。像这样的情况下,只有汇总日志就有问题,因为它只聚合一小部分请求。
所以我们开始研究几个OLAP系统。我们研究的第一个系统是Druid。我们对前端(Pivot和以前的Caravel)是如何切分数据的能力印象很深刻,他使我们能够生成具有任意维度的报告。 Druid已经被部署在类似的环境中,每天超过1000亿事件,所以我们对它可以工作很有信心,但是在对抽样数据进行测试之后,我们无法证明数百个节点的硬件成本。几乎在同一时间,Yandex开源了他们的OLAP系统ClickHouse。
ClickHouse的系统设计更加简单,集群中的所有节点具有相同的功能,使用ZooKeeper进行协调。我们建立了一个由几个节点组成的集群,发现性能相当可观,所以我们继续构建了一个概念验证。我们遇到的第一个障碍是缺少工具和社区规模的规模太小,所以我们钻研了ClickHouse设计,以了解它是如何工作的。
ClickHouse不直接支持Kafka,因为它只是一个数据库,所以我们使用Go写了一个适配器服务。它读取来自Kafka的使用Capn Proto编码的消息,将它们转换为TSV,并通过HTTP接口分批插入ClickHouse。后来,我们讲ClickHouse的HTTP接口替换为GO SQL驱动,以提高性能。从那以后,我们就开始为该项目提供了性能改进。我们在性能评估过程中学到的一件事是,ClickHouse写入性能很大程度上取决于批量的大小,即一次插入的行数。为了理解为什么,我们需要进一步了解了ClickHouse如何存储数据。
ClickHouse用于存储的最常见的表引擎是MergeTree系列。它在概念上类似于Google的BigTable或Apache Cassandra中使用的LSM算法,但它避免了中间内存表,并直接写入磁盘。这使得写入吞吐量非常出色,因为每个插入的批次只能通过“主键”进行排序,压缩并写入磁盘以形成一个段。没有内存表也意味着他仅仅追加数据,并且不支持数据修改或删除。当前删除数据的唯一方法是按日历月份删除数据,因为段不会与月份边界重叠。 ClickHouse团队正在积极致力于使这个功能可配置。另一方面,这使得写入和段合并无冲突,因此吞吐量与并行插入的数量成线性比例关系,直到I/O跑满。但是,这也意味着它不适合小批量生产,这就是为什么我们依靠Kafka和插入器服务进行缓冲的原因。 ClickHouse在后台不断合并,所以很多段将被合并和写多次(从而增加写放大),太多未合并的段将触发写入限流,直到合并完成。我们发现,每秒钟每张表的插入一次效果最好。
表读性能的关键是索引和数据在磁盘上的排列。无论处理速度有多快,当引擎需要从磁盘扫描太多数据时,这都需要大量时间。ClickHouse是一个列式存储,因此每个段都包含每个列的文件,每行都有排序值。通过这种方式,可以跳过查询中不存在的列,然后可以通过向量化执行并行处理多个单元。为了避免完整的扫描,每个段也有一个稀疏的索引文件。鉴于所有列都按“主键”排序,索引文件仅包含每第N行的标记(捕获行),以便即使对于非常大的表也可以将其保留在内存中。例如,默认设置是每隔8192行做一个标记。这种方式只需要122,070个标记来具有1万亿行的表格进行索引。在这里可以查看ClickHouse中的主键,深入了解它的工作原理。
使用主键列查询时,索引返回考虑行的大致范围。理想情况下,范围应该是宽而连续的。例如,当典型用法是为单个区域生成报告时,将区域放在主键的第一个位置将导致按每个区域进行排序,使得磁盘读取单个区域连续,而如果按主要时间戳排序则在生成报告是无法保证连续。行只能以一种方式排序,因此必须仔细选择主键,并考虑典型的查询负载。在我们的例子中,我们优化了单个区域的读取查询,并为探索性查询提供了一个带有采样数据的独立表格。从中吸取的教训是,我们不是试图为了各种目的而优化索引,而是分解差异并多加一些表。
这样专有化设计的结果就是在区域上聚合的表格。由于没有办法过滤数据,因此扫描所有行的查询都要昂贵得多。这使得分析师在长时间计算基本聚合时不那么实际,所以我们决定使用物化视图来增量计算预定义聚合,例如计数器,唯一键和分位数。物化视图利用批量插入的排序阶段来执行生产性工作 - 计算聚合。因此,在新插入的段被排序之后,它也会生成一个表格,其中的行代表维度,而列代表聚合函数状态。聚合状态和最终结果之间的区别在于,我们可以使用任意时间分辨率生成报告,而无需实际存储多个分辨率的预计算数据。在某些情况下,状态和结果可能是相同的 - 例如基本计数器,每小时计数可以通过累计每分钟计数来产生,但是对独特的访问者或延迟分位数求和是没有意义的。这是聚合状态更有用的时候,因为它允许有意义地合并更复杂的状态,如HyperLogLog(HLL)位图,以便每小时聚合生成每小时独立访问者估计值。缺点是存储状态可能比存储最终值要昂贵的多 - 上述HLL状态在压缩时大概有20-100字节/行,而计数器只有8字节(平均压缩1个字节)。使用这些表可以快速地将整个区域或站点的总体趋势形象化, 并且我们的 API 服务也使用它们做简单查询。在同一位置同时使用增量聚合和没有聚合的数据, 我们可以通过流处理完全简化体系结构。
我们使用12个6TB磁盘做RAID-10,但在一次磁盘故障之后重新进行了评估。在第二次迭代中,我们迁移到了RAID-0,原因有两个。首先,不能热插拔有故障的磁盘,其次阵列重建花费了数十个小时,这降低了I/O性能。更换故障节点并使用内部复制通过网络(2x10GbE)填充数据比等待阵列完成重建要快得多。为了弥补节点故障的可能性较高,我们切换到3路复制,并将每个分片的副本分配到不同的机架,并开始规划复制到单独的数据仓库。
另一个磁盘故障突出了我们使用的文件系统的问题。最初我们使用XFS,但它在复制过程中开始在同一时间从2个对等点进行锁定, 从而在完成之前中断了段复制。这个问题表现为大量I/O活动,由于损坏的部分被删除,磁盘使用量增加很少,所以我们逐渐迁移到了ext4,该文件系统就没有这个问题。
当时我们只依靠Pandas和ClickHouse的HTTP接口进行临时分析,但是我们希望使分析和监控更容易。 因为我们知道Caravel(现在更名为Superset ),我们就把它和ClickHouse进行了整合。
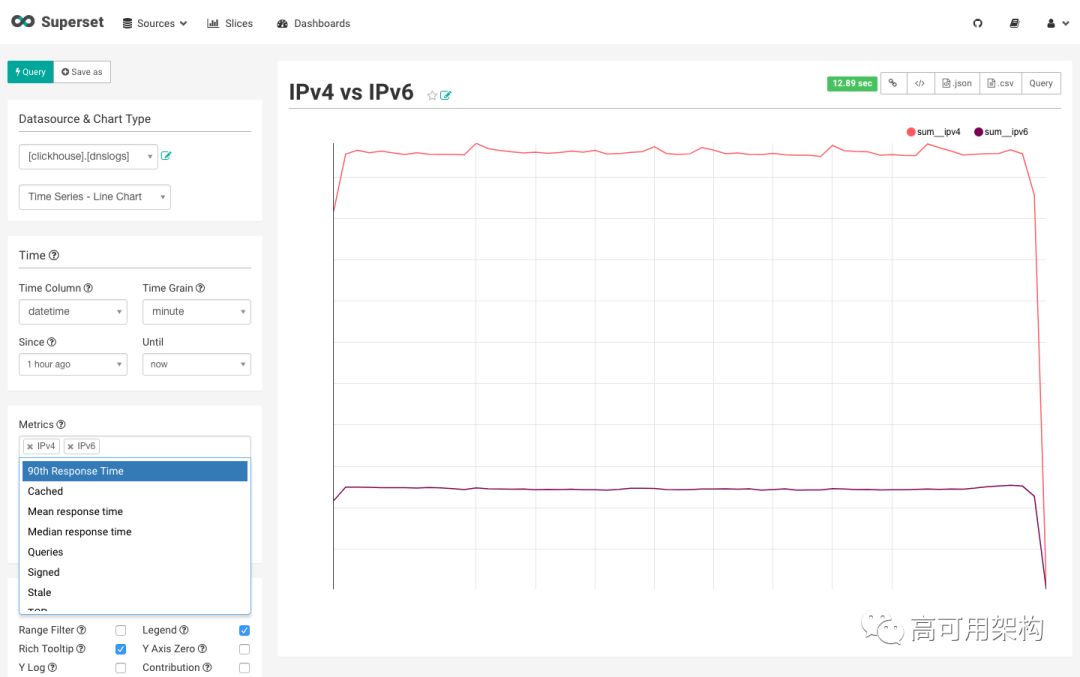
Superset是一个直观的数据可视化平台,它允许分析人员在不写一行SQL的情况下交互地切片和切分数据。 它最初是由AirBnB为Druid构建和开源的,但是随着时间的推移,它已经通过使用SQLAlchemy(一种抽象和ORM)为数十种不同的数据库方言提供了基于SQL的后端的支持。 所以我们编写并开源了一个ClickHouse方言,并集成到Superset。
Superset为我们提供了特别的可视化服务,但是对于我们的监控用例来说,它仍然不够完善。 在Cloudflare,我们大量使用Grafana来可视化所有指标,所以我们将它与Grafana集成并进行开源。
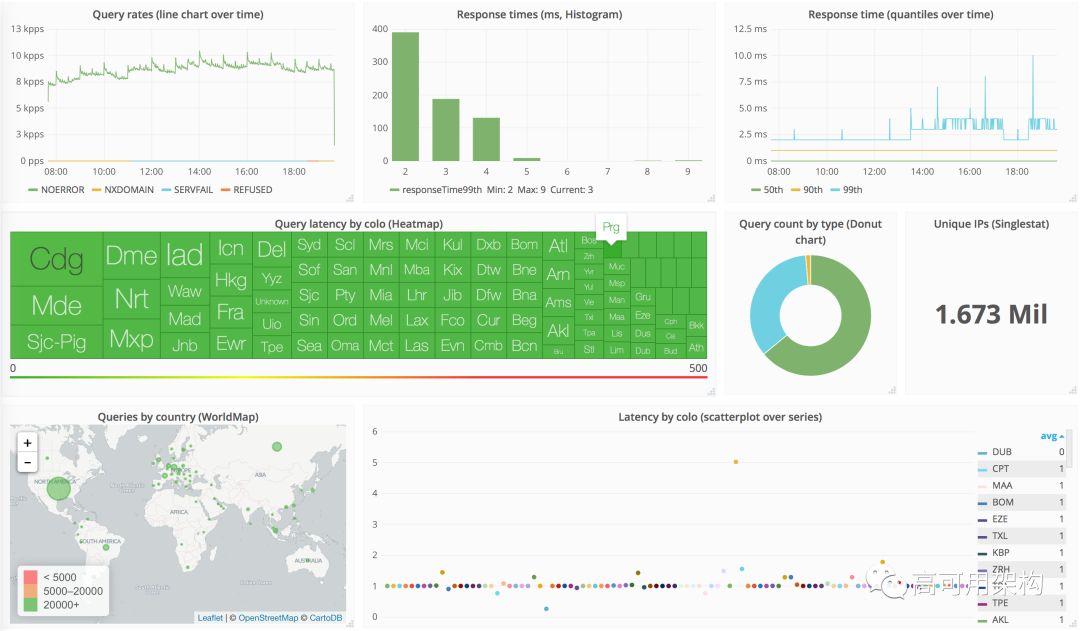
它使我们能够用新的分析数据无缝地扩展我们现有的监测仪表板。 我们非常喜欢这个功能,因此我们希望能够为用户提供同样的能力来查看分析数据。 因此,我们构建了一个Grafana应用程序,以便可视化来自Cloudflare DNS Analytics的数据。 最后,我们在您的Cloudflare仪表板分析中提供了它。 随着时间的推移,我们将添加新的数据源,维度和其他有用的方法来显示Cloudflare中的数据。返回搜狐,查看更多




还没有评论,来说两句吧...
发表评论