SEO优化往大了讲海纳百川,往小点讲也有很多重要元素。抓取和索引这两件事就是SEO领域中简单而又重要的观念,熟悉了解它们之后便可以优化搜索引擎蜘蛛抓取、索引你的网站。
Google官方将它称为Google Spider、Google Bot,我们便将其称之为蜘蛛,想象一下互联网便是一个又一个的蜘蛛网连在一起,而搜索引擎本身有属于它的软件,就像是蜘蛛一样在巨大的网络上爬行,并收集 资讯。
做 SEO工作,维持网路蜘蛛与网站之间良好的关系是非常重要的,你必须要了解各大搜寻引擎蜘蛛的效能以及规范,并尽量让它能够完整抓取你网站上的优质内容。
早些年,Bing的蜘蛛太大容量的网站内容会无法抓取,这是它本身的功能限制,你必须要把最好的内容往前方,如果容量太大的话,后边的内容Bing是抓不到的。
抓取 ( Crawl) 便是指搜索引擎捕捉你网站上的资料的行为,包括网站的关键字、内容、反向链接等等,刷取完毕之后便会通过索引蜘蛛在爬完你的资料之后,将所有内容进行演算、归档,并且收录到搜索引擎中,这个建档、收录的过程被称之为( Index )。
索引完成之后,用户才能在搜索引擎中找到你的网站,简单来讲,先有抓取才会有索引,通过Google站长工具,我们可以看到网站被抓取、索引的情况。
抓取和索引是完全不同的两件事,有可能你的页面被Google正常抓取,却没有将页面索引到搜索引擎上,这样的情况一般来讲就很有可能是你的网站有违规的行为,又或者排名太差,在搜索引擎上根本找不到自己的页面。
抓取的优化功能就是要确定Google、Bing在抓取、并且是完整的抓取整站的资料,有可能因为某处的网站结构以及HTML语法的错误,导致它看不到你的网站,这是非常致命的一件事情。
当然,有时候你也不希望蜘蛛去抓取某些个网站,比如说有页面未完成、还在测试阶段,你不希望Google看到这个页面,那就必须使用些特殊的语法,阻止蜘蛛抓到这些页面的资料。
先排除排名的情况外,先确保你的页面都有正常的建立搜索引擎,并且某些页面会影响用户体验,你并不希望被建立进搜索引擎,你就要使用meta robots来进行SEO工作。
meta robots以及robots.txt的工作分别是阻止Google 抓取、索引你的页面,可是我们明明巴不得搜索引擎把整站的页面全都给抓取、索引,为什么还要阻止搜索引擎呢?
这年头已经不是单纯SEO排名、流量高就有用的,为了能够让网站产生价值,制造转换,所以使用体验相对重要,如果你有些页面会给用户带来不好的体验,可以用这个办法去阻止该页面出现在Google搜索结果中。
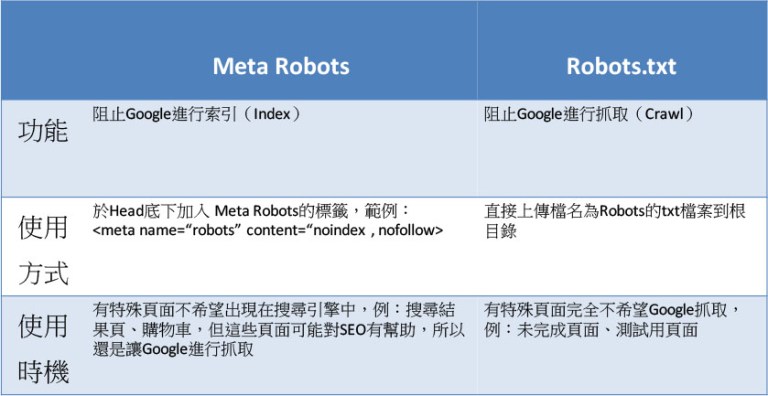
Robots.txt可以阻止搜索引擎抓取你的资料,如果你使用了robots.txt来阻挡搜索引擎,那么搜索引擎将会略过你所阻挡的页面,不去做抓取。
但meta robots 就不同了,他在索引层面阻止搜索引擎索引你的页面,但Google还是有抓取你的网站资料的,但究竟为什么我们要这样做?
大多数情况下,我们都不会使用Robots.txt来阻止搜索引擎抓取我们的网站,除非你确定这个页面对SEO有负面影响,若你有页面不希望出现在搜索引擎上的话,还是用Meta Robots控制索引就好,除非有以下的情况:
网站页面正在开发中,并且开发时间比较长,甚至还需要进行修改、索引,这时候被蜘蛛抓取、索引,可能会给用户搜索带来错误的信息,而且未完成的页面也会影响用户的使用体验。
了解meta robots以及robots.txt之后,你可以优化网站的抓取及索引状况,阻止特定页面跟被抓到或是被索引。
Google官方有明确的声明,meta robots和robots.txt确实可以告诉Google你希望那些页面不要被抓取以及索引,Google也会尽量尊重你的决定。
然而,Google官方不保证搜索引擎会完全服从meta robots和robots.txt,肉搜索引擎认为你的网站有很多很多反向链接、流量很高、内容很优质、是非常非常棒的网站,它也有可能执意要抓取、索引你的网站。

谷歌竞价推广怎么做?Google AdWords教程、Google seo优化技巧尽在跨境电商新媒体-雨果网!





还没有评论,来说两句吧...
发表评论